通关栈溢出(一):原理及初级攻击
前段时间停博了,因为工作的问题不太方便将一些工作内容以博客的方式展现出来,现在开始打算用提取知识点的方式记录下这些经验。太久不写博客还是不太行
之前写过几篇栈溢出的文章,内容不太全面,零零散散,因此从本文开始打算做个栈溢出的专栏,主要介绍栈溢出相关的问题,包括初级的攻击、jmp esp,SEH、DEP、ALSR、ROP等,算是一篇通关文吧。
OS: Windows XP SP2, Window 7
Tools:Ollydbg、IDA pro、AsmToE(汇编转机器码)、010Editor、VC6.0、Xcode、Windbg、VS7.0
Book: 《0day安全:软件漏洞分析技术》
知识点的主要来源是”0day安全:软件漏洞分析技术”和网络,但发现它内部80%漏洞利用代码均无法直接在自己的机器上运行。因此本通关专栏不会完全按书的内容规划,在必要的时候会自行实现
栈
每个进程都有一个独立的虚拟地址空间,这些虚拟地址空间在x86里被称为segment,例如Data Segment、Text Segment、stack、heap等等。
Android中,进程里的虚拟地址空间是由vm_area_struct结构组成的。全局维护一个vm_area_struct链表,用于串联所有已分配的空间。当使用mmap申请一个内存空间时,就会找到进程中一块连续且符合大小的区域,创建一个vm_area_struct结构用于标识本区域块,然后将其链接到进程的vm_area_struct链表中。
栈向上增长,底部为高字节,上部为底字节。
函数调用的汇编过程
需要用到的关键词:
EBP: 栈底指针
ESP: 栈顶指针
EIP:寄存器存放下一个CPU指令存放的内存地址,当CPU执行完当前的指令后,从EIP寄存器中读取下一条指令的内存地址,然后继续执行
目标函数:
1 | char name[] = "1234567"; |
- 将目标函数需要的参数从右到左依次入栈。PUSH c, PUSH b, PUSH a
- 将函数的返回地址入栈,也就是执行完这个函数后应该执行的下一条指令的地址。
- 跳转到目标代码块。2和3合为CALL指令。CALL address of func
- 调用方的栈顶属于被调用方的栈底,因此保存该信息,便于接下来分配新的栈帧供func使用。 MOV ebp, esp, PUSH ebp
- 抬高栈帧. SUB esp, 0x40. 这也就是给函数分配内存空间,0x40是根据目标函数func的局部变量确定的(程序在链接-编译-汇编的过程中就已生成了size,解析值即可),这里只是示例。
- 创建局部变量,4个字节为一组。buf[8]因此会被分为两部分: buf[4~7], buf[0~3]
- do something
- 程序执行完毕,还原调用环境,也就是各寄存器的值。降低esp,也就是释放之前分配的栈帧资源。 add esp, 0x40
- 程序的最后一行,是RETN,也就是返回。从CPU从EIP中取出下一条指令的内存地址然后执行,这样就完成了函数调用的回溯
栈溢出
在上面的1~6步完成后,栈的结构应该是这样的。
高地址在下,低地址在上
| buf[0~3] |
|---|
| buf[4~7] |
| ebp |
| Return Address |
| Param a |
| Param b |
| Param c |
从函数调用的过程来说,函数执行完毕后执行的下一个指令地址就是ReturnAddress。
如果我们想让程序在执行完func后跑去执行我们自己构造的恶意代码,只需修改ReturnAddress的值即可。
以前的流程是: main->func->main
修改func的返回值后:main->func->shellcode
C允许开发者直接对内存中的某个地址做修改,它本身也存在内存不安全函数。常见的如:gets、strcpy、strcat、scanf等。
func使用strcpy将name中的所有内容全拷贝到buf中,如果name的内容超过buf的大小,那么接下来的内容就会覆盖掉buf下面的ebp、return address等。如果我们让name中先存放12字节的任意数据(buf占8个字节,ebp占4个字节),那么name[13~16]就会覆盖掉Return address,当func返回值EIP指向的就是name[13~16]的地址了。
Shellcode
即恶意代码。指攻击者用于实时攻击的一段指令,指令的形式不限,不管是高级语言Java、Python,或者是汇编、机器指令,均可称作Shellcode。
本文的栈溢出,因为是直接将恶意代码插入到栈当中,在程序返回时恶意执行,没有将代码解析和转换成机器指令的流程,因此需要直接存入机器指令。
本文生成Shellcode的方法如下:
- 编写汇编
- 使用UltraEdit或者AsmToE 将汇编转为机器指令
- 通过在机器指令码首部插入 \x 的方式将所有指令串联起来
例如:
机器指令为 83 EC 50,
对应的汇编为sub esp,50h
Shellcode为\x83\EC\50
TIPS:
在生成Shellcode时,需要按照漏洞的类型仔细配置.
例如本文的攻击面是strcpy,而strcpy有个特性,一旦读取的字符串中包含00,就认为这个字符串的读取已经结束了。因此我们本次的Shellcode一定不能出现00的机器码。对于memcpy命令来说,就不存在这个问题
Shellcode的加载与调试
Shellcode最常见的形式是把字符转换为机器码并存储在一个字符数组中,例如:
1 | char name[] = "\x41\x41\x41\x41\x41\x41\x41\x41" // name[0]~name[7] |
直接将Shellcode填入漏洞程序的缓冲区去调试一般是不可取的,因为我们需要确认程序出错是因为Shellcode本身的问题还是因为Shellcode覆盖了程序的某些核心值导致运行出错,这就要我们动态调试了。所以一般编写和调试Shellcode会用如下的方式:
1 | char shellcode[] = '16进制机器码'; |
lea会将shellcode的地址存入到Eax中,ret指令会把push进去的shellcode地址弹给Eip,让处理器跳转到栈区去执行shellcode,从而实现调用
上面这段代码也等同于 eip = shellcode, call/jmp eip
一、攻击:指定Shellcode的地址
上文说到,将func的ReturnAddress替换为Shellcode在内存中的地址即可正确执行代码。那如何获取Shellcod在内存中的地址呢?
分两种情况:
- 只考虑本地环境
- 通用环境。即所有的windows都能跳转到Shellcode的首地址。
先分析我们的攻击代码,它由两部分构成。
一部分是覆盖代码A,用于覆盖buf的所有空间以及EBP(这一块其实并不算Shellcode)
另一部分就是Shellcode,它的首部地址就是我们的目标。
A可以完全或部分包含Shellcode,也可以将shellcode排列在A之后。
获取Shellcode的地址有两个方法,一个是直接打印,一个是使用调试工具ida pro、ollydbg动态调试。
1 | // Shellcode在A之后 |
因为只考虑本地环境这种攻击方法兼容性太差,因此代码就不贴上来了,直接介绍下面的第二种攻击方式。jmp esp
二、攻击:JMP esp
| 函数返回时栈中的情况 |
|---|
| Return Address |
| Param a |
| Param b |
当我们使用ollydbg调试函数返回的情况,栈内的情况如上图。之前已经分配的buf和ebp已被弹出。只剩返回值地址,函数的入参a、b、c
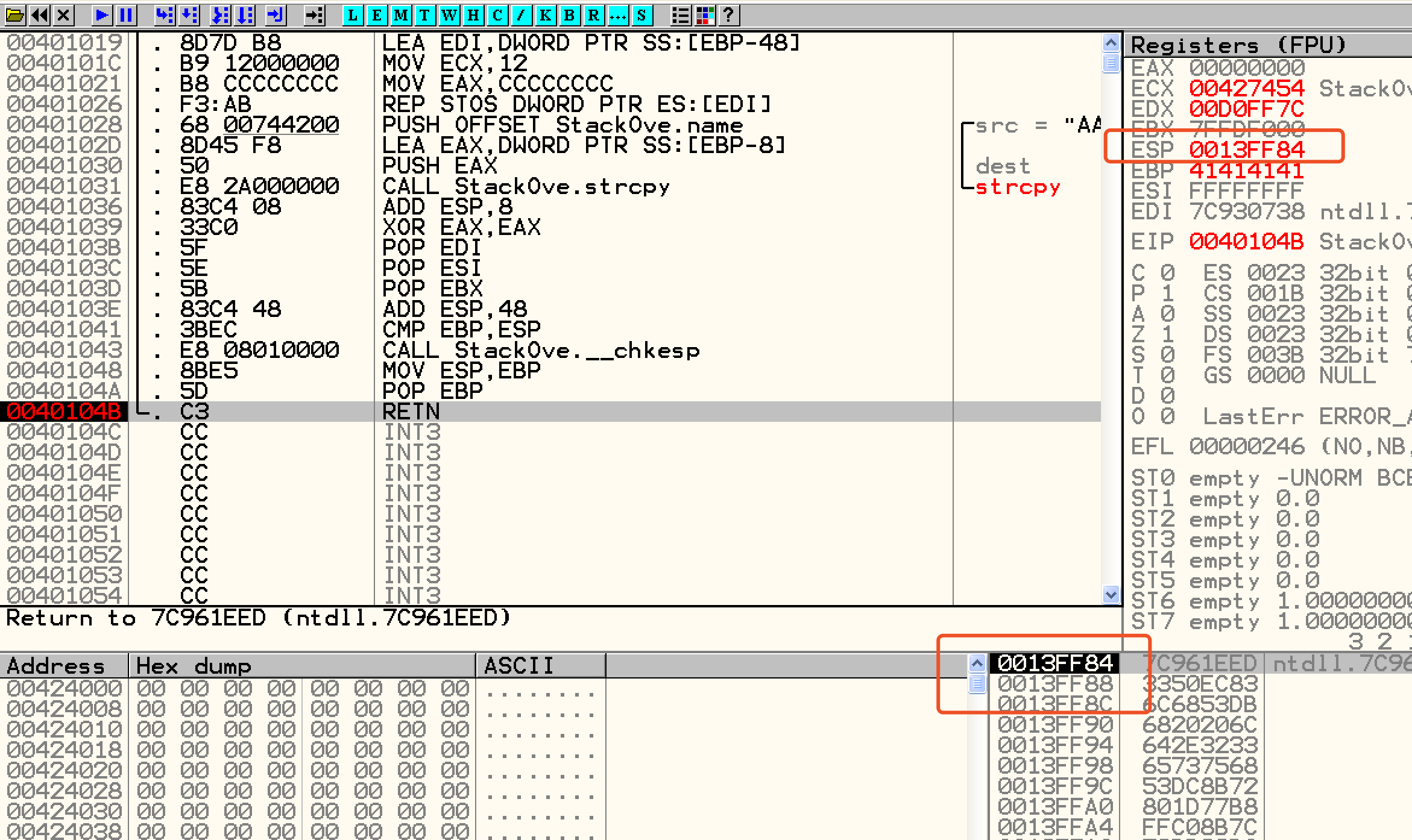
此时,函数还未返回,ESP指向0013FF84,也就是返回后程序会从13FF84取出地址7C961EED并跳转 .
而当我们手动点击下一步,程序跳转到了地址7C961EED,但此时esp的值也变为了0013FF88。
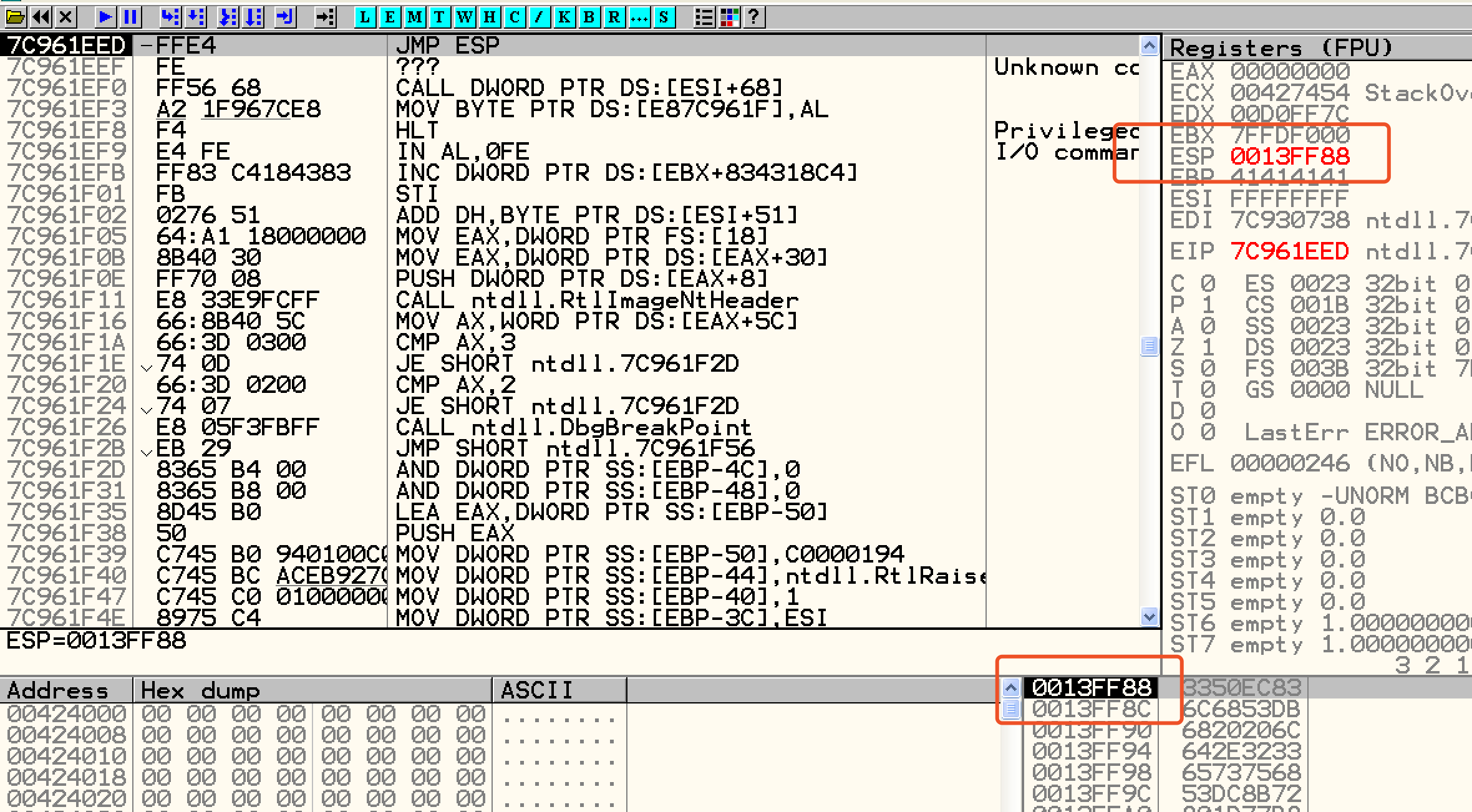
这说明什么呢?
说明不管程序如何返回,在执行完RETN后ESP一定会指向ReturnAddress的下一个地址。本文也就是指向Param a的地址。我们可以先让Shellcode从Param a的位置开始填充,再让ReturnAddress跳转的地址指向一个jmp esp命令,那么此时再点击单步执行,那么程序就会从ESP所指向的地址中取值并执行,这样也就跳转到我们的Shellcode了
因此整体的攻击流程就可以变更为:
- 任意非00的指令覆盖buffer和EBP
- 从程序已经加载的dll中获取他们的jmp esp指令地址。
- 使用jmp esp的指令地址覆盖ReturnAddress
- 从下一行开始填充Shellcode
获取jmp esp地址的方法为:
打开windbg,File->attach a process.
lm 指令查看现在加载了哪些库,获取它的start地址和end地址。对于win32程序而言,他们都会加载kernel32.dll和ntdll.dll
jmp esp的机器码为 FF E4。 使用指令: s start地址 end地址 FF E4 即可查看库中包含jmp esp的地址address。
- u address 指令可以查看该地址处的汇编,检验是否是jmp esp
- 校验无误后保存备用
获取jmp esp后,我们需要用16进制表示它。这里有个小tips,因为windows操作系统是小端显示,那么对应的16进制就应该反着写。
例如,我们通过windbg获得的jmp esp地址为7c961eed,那么它的16进制就是0xed1e967c,即两位一组,反着写。
编写Shellcode
接下来,我们就可以开始编写Shellcode。编写Shellcode有多种方式,最快捷的是使用metasploit直接生成payload。本文用弹出一个计算器作为示例。
在C中,如果我们要弹出一个计算器,代码如下:
1 |
|
首先我们需要载入kernel32.dll(win32默认已载入,这里仅作演示,实际可删除这行代码),然后调用它WinExec这个方法,传入两个参,一个参是0,一个参是”calc.exe”。之后调用ExitProcess,传入参数0,退出程序。
获取LoadLibrary和ExitProcess在内存中的地址
LoadLibrary和ExitProcess属于kernel32.dll的功能,kernel32.dll在程序启动时就已默认加载,那么只需从内存中获得这两个方法的地址即可。
1 |
|
保存他们的地址,接着就是编写汇编去调用这两个方法了
1 | sub esp,0x40 // 抬高栈帧 |
将这段汇编拖入AsmToE,获取机器码,并用\x替换空格。
Shellcode和完整代码如下:
1 |
|
小结
攻击二中,LoadLibrary、WinExec、ExitProcess的地址是我们手动获取的,这意味着这个溢出shellcode在不同的操作系统版本上均需要重新获取对应的地址方可使用,有办法可以编写通用脚本吗?
三、攻击:编写系统版本通用的Shellcode
在本次的Shellcode中,我们调用了如下的函数:WinExec、LoadLibrary、ExitProcess。
Target:编写通用Shellcode的目的就是要让我们的Shellcode能在目标OS中自行定位以上3个函数在内存中的实际位置并进行调用。
原理:
- 定位dll中函数导出表的位置,拿到它的导出函数名列表
- 做hash比较查找指定函数(WinExec等),比较成功后从RVA中获取它相对于dll的偏移地址
- 再加上dll的基址就能得到该函数在内存中的绝对地址。
细节:
所有的win32程序都会加载ntdll.dll和kernel32.dll,如果要定位kernel32.dll中的API地址,可以用如下方法:
- 首先通过段选择字FS在内存中找到当前的线程环境块TEB
- 线程环境块偏移位置为0x30的地方存放着指向进程环境块PEB的指针
- 进程环境块PEB中偏移位置为0x0C的地方存放着指向PEB_LDR_DATA结构体的指针,其中存放着已经被进程装载的动态链接库的信息。
- PEB_LDR_DATA结构体偏移位置为0x1C的地方存放着指向模块初始化链表的头指针。
- 模块初始化链表按顺序存放着PE装入运行时初始化模块的信息,第一个链表节点是ntdll.dll,第二个节点就是kernel32.dll
- 找到kernel32.dll节点后,在其基础上再偏移0x08就是kernel32.dll在内存中的加载基地址。
- 从kernel32.dll的加载基址算起,偏移0x3C的地方就是其PE头
- PE头偏移0x78的地方存放着指向函数导出表的指针
- 至此,我们可以按如下方式在函数导出表中算出所需函数的入口地址。
- 导出表偏移0x1C处的指针指向存储导出函数偏移地址(RVA)的列表
- 导出表偏移0x20处的指针指向存储导出函数名的列表
- 函数的RVA地址和名字按照顺序存放在上述两个列表中,我们可以在名称列表中定位到所需的函数是第几个,然后在地址列表中找到对应的RVA
- 获得RVA后,再加上前边已经得到的动态链接库的基地址,就能算出API此时在内存中的绝对地址
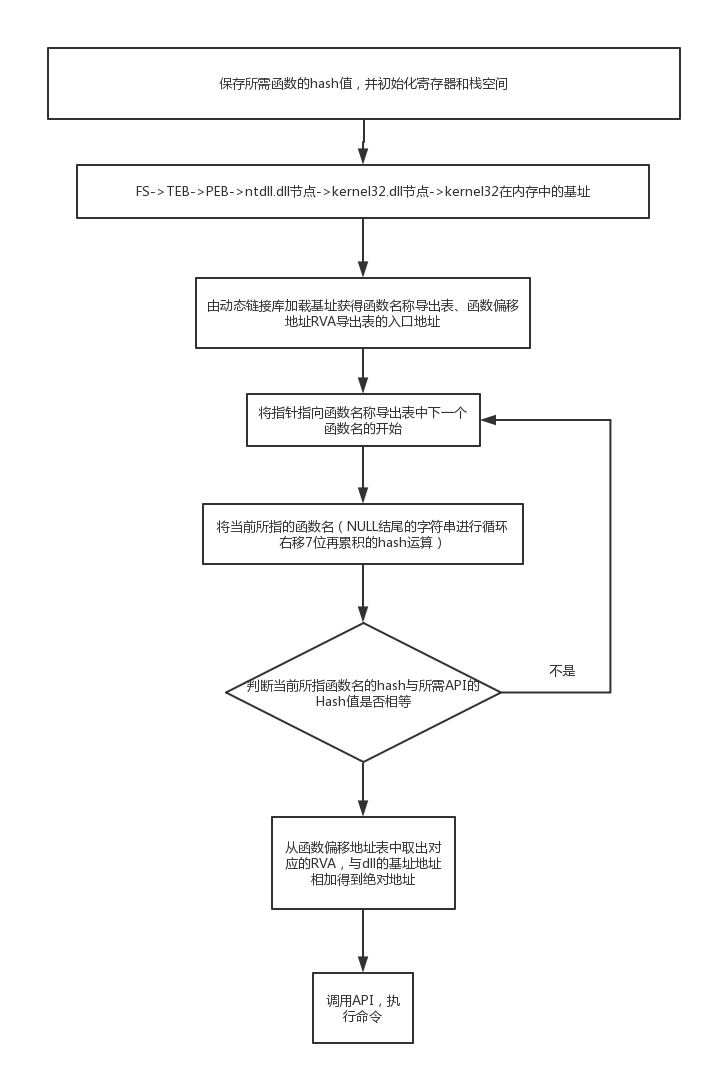
代码如下:
获取函数名hash的代码如下:
1 |
|
在将hash压入栈中之前,先将增量标识DF清零,因为当Shellcode是利用异常处理机制而植入的时候,往往会产生标志位的变化,使Shellcode中的字串处理方向发生变化而产生错误。
因此使用 CLD指令就可增大ShellCode的通用性
完整代码如下:
复制_asm包裹的汇编,拖入AsmToE转换为机器指令即可生成shellcode的16进制
1 |
|
收尾
本篇的shellcode尚不完善,jmp esp目前也是手动获取的,但本文的主要目的是在于梳理栈溢出的基础,在接下来的几篇文章中,会不断完善这个Shellcode,包括绕过一些安全措施等等。

