Dex文件结构分析
Dex文件结构分析。
本文源码均摘自8.0分支
Dex和class字节码的区别
一句话概括:dex是优化后的class字节码。
在打包的过程中,dx工具会将class转换为dex,只要的操作流程为:
对java类文件进行重新排序,建立统一的常量池,消除冗余的信息。
E.G:
在java中,如果类A和类B都调用到了类C的FunctionC方法,则FunctionC的方法签名会被复制到A和B中。
这也就造成了多个不同的文件可能会同时包含多个相同的方法签名。字符串等常量也类似。
因此dx工具建立了一个统一的资源常量池,将所有class文件二次处理,消除其中的冗余项。
Dex文件的结构从上到下也就是:
| 名称 | 含义 |
|---|---|
| dex_header | 文件头。包含本dex的基本内容和文件其他区域的索引 |
| string_ids | 字符串索引 |
| type_ids | 类型的索引 |
| proto_ids | 方法声明结构体的索引 |
| field_ids | 域的索引 |
| method_ids | 方法的索引 |
| class_defs | 类的定义 |
| data | 数据区 |
| link_data | 链接数据区 |
dex中的数据类型
| 类型 | 含义 |
|---|---|
| u1 | 等同于uint8_t,表示1字节的无符号数 |
| u2 | 等同于uint16_t,表示2字节的无符号数 |
| u4 | 等同于uint32_t,表示4字节的无符号数 |
| u8 | 等同于uinit64_t,表示8字节的无符号数 |
| sleb128 | 有符号LEB128,可变长度1~5字节 |
| uleb128 | 无符号LEB128,可变长度1~5字节 |
| uleb128p1 | 无符号LEB128值加1,可变长度1~5字节 |
每个LEB128由1~5个字节组成,每个字节只有7个有效位。最高位是一个标志位。
如果LEB128的第一个字节的最高位为1,表示需要用到下一个字节
如果第二个字节的最高位也为1,表示也会会用到第三个字节。
以此类推。如果读取第五个字节后下一个字节最高位仍位1,则表示该dex无效,虚拟机在验证dex的时候就会失败返回。
以下为Leb128.h文件中读取uleb128的函数:
1 | /* |
读取sleb128:
有符号的LEB128其实是一样的,只是对字节的最高有效位做了符号拓展
1 | /* |
DexHeader
1 | /* |
magic
文件标识符。 64 65 78 0A 30 33 35 00,换为ascii也就是 dex\n035 最后的4位为版本标识
占用8个字节
checksum
dex文件的校验和,用于判断dex是否被修改以及合法性,占用4字节
计算方式是使用alder32算法计算除magic和checksum之外的所有区域的值。
也就是下面除首部12字节外的所有数据(magic 8位,checksum 4位)
1 | /** |
signature
校验码,用于判断dex是否被修改以及合法性。占用20字节
计算方式是使用SHA1算法计算除magic、checksum、signature之外的所有区域的值,也就是除首部32字节以外的所有数据。
1 | /** |
Filesize
文件的总大小。4字节
headerSize
整个dexheader的大小,一般固定为0x70
endianTag
DEX运行环境的cpu字节序,预设值ENDIAN_CONSTANT等于0x12345678,表示默认采用Little-Endian字节序。也就是小端显示。
What is 字节序?
字节顺序是指占内存多于一个字节类型的数据在内存中的存放顺序,通常有小端、大端两种字节顺序。小端字节序指低字节数据存放在内存低地址处,高字节数据存放在内存高地址处;大端字节序是高字节数据存放在低地址处,低字节数据存放在高地址处。
字节序不是由操作系统决定的,而是由cpu架构决定的
大端显示:12345678
低—————–>高
12 34 56 78
小端显示:12345678
低—————–>高
78 56 34 12
之所以需要用到字节序,是因为不同语言的数据存储顺序方式不同。C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的,而JAVA编写的程序则只采用bigendian方式来存储数据。如果c++的程序想要和java程序联通,那么他们的字节顺序就必须要注意。
简单理解就是:一个数据存储的协议。
其他
- linkSize和linkOff:指定链接段的大小与文件偏移,大多数情况下它们的值都为0。link_size:LinkSection大小,如果为0则表示该DEX文件不是静态链接。link_off用来表示LinkSection距离DEX头的偏移地址,如果LinkSize为0,此值也会为0。
- mapOff:DexMapList结构的文件偏移。
- stringIdsSize和stringIdsOff:DexStringId结构的数据段大小与文件偏移。
- typeIdsSize和typeIdsOff:DexTypeId结构的数据段大小与文件偏移。
- protoIdsSize和protoIdsSize:DexProtoId结构的数据段大小与文件偏移。
- fieldIdsSize和fieldIdsSize:DexFieldId结构的数据段大小与文件偏移。
- methodIdsSize和methodIdsSize:DexMethodId结构的数据段大小与文件偏移。
- classDefsSize和classDefsOff:DexClassDef结构的数据段大小与文件偏移。
- dataSize和dataOff:数据段的大小与文件偏移。
DexMapList
Dalvik虚拟机解析dex文件的内容,最终将其映射为DexMapList数据结构。
DexHeader结构的mapOff字段指明了DexMapList结构在dex文件中的偏移。
每一种数据均是一种DexMapItem类型,存放在DexMapList中。
某一类的DexMapItem包含的数据位:这类数据有多少个,他的文件偏移是多少。
1 | /* |
这上面的type值有:
1 | /* map item type codes */ |
随便建了一个项目,生成debug包,解压dex,拖入010 Editor,得到dex的二进制数据。
以下为DexHeader,总大小为0x70
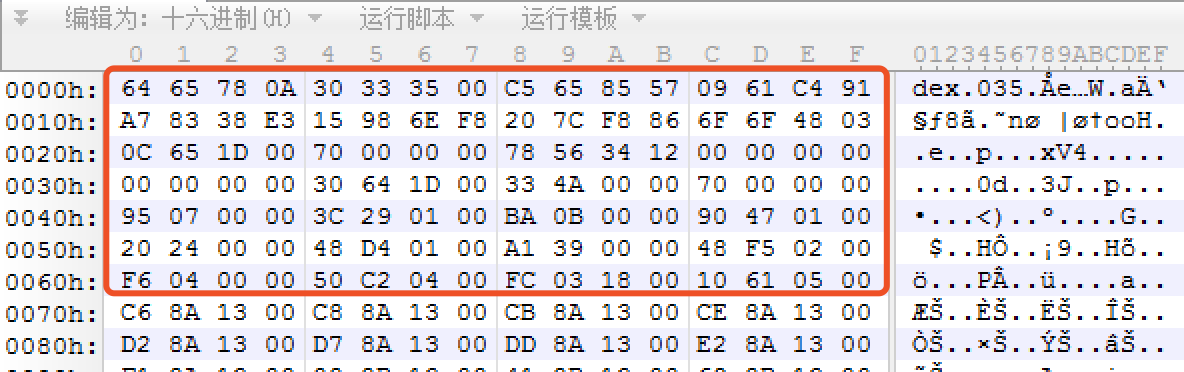
按前面的DexHeader偏移表计算可知,mapoff所在的位置为53~56(signature结束于32字节,mapoff前面有5个4字节的)。一行为16字节,故mapoff的值为:30 64 1D 00,因为是小端显示,所以它的值为0x1d6430。
Tips:直接滚动到屏幕最下面就行了
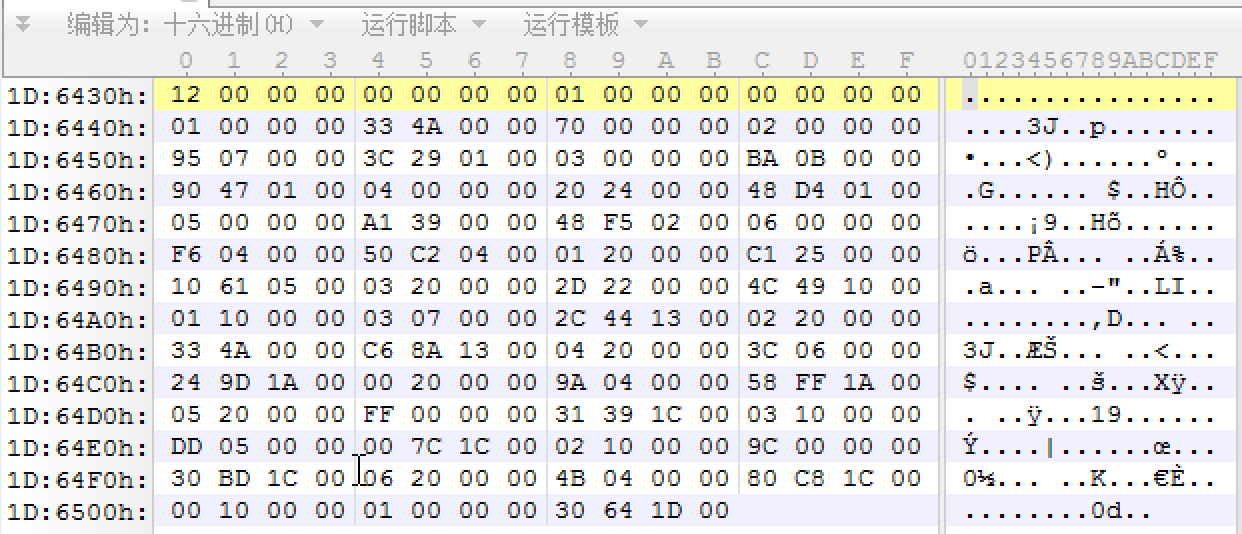
它的第一个字段为12,对应十进制的18,表明接下来会有18个DexMapItem结构(总共就只有20个)
前面4个字节为size(12 00 00 00),后面依次的就是各个DexMapItem的内容。
例如:接下来的来的 00对应type,占用两个字节,表示为header。跟着的00表示unused,再跟着的 01 00 00 00表示size,类型的个数。最后的00 00 00 00 表示偏移。
所以第一行的内容(除开12 00 00 00)为:DexHeader类型,个数为1,偏移为0
注意是小端显示
举个例子,整理一下:
| 类型 | 个数 | 偏移 |
|---|---|---|
| kDexTypeHeaderItem | 0x01 | 0x0 |
| kDexTypeStringIdItem | 0x4A33 | 0x70 |
| kDexTypeTypeIdItem | 0x795 | 0x1293C |
这里只列举了3个,剩下的太多,不写了。
简单校验一下,stringId起始的位置为0x70,数量有0x4A33个,每个占用4字节,也就是0x128cc,加上0x70,最终等于0x1293c,也就是TypeIdde的偏移。表明上面的表格正确。
对于stringId来说,表明在0x70处有0x4A33个String类型。从上面DexHeader的那张图可以发现,0070h位置处的4个字节为C6 8A 13 00,也就表明第一个string的字符串数据位于0x138AC6(小端显示).
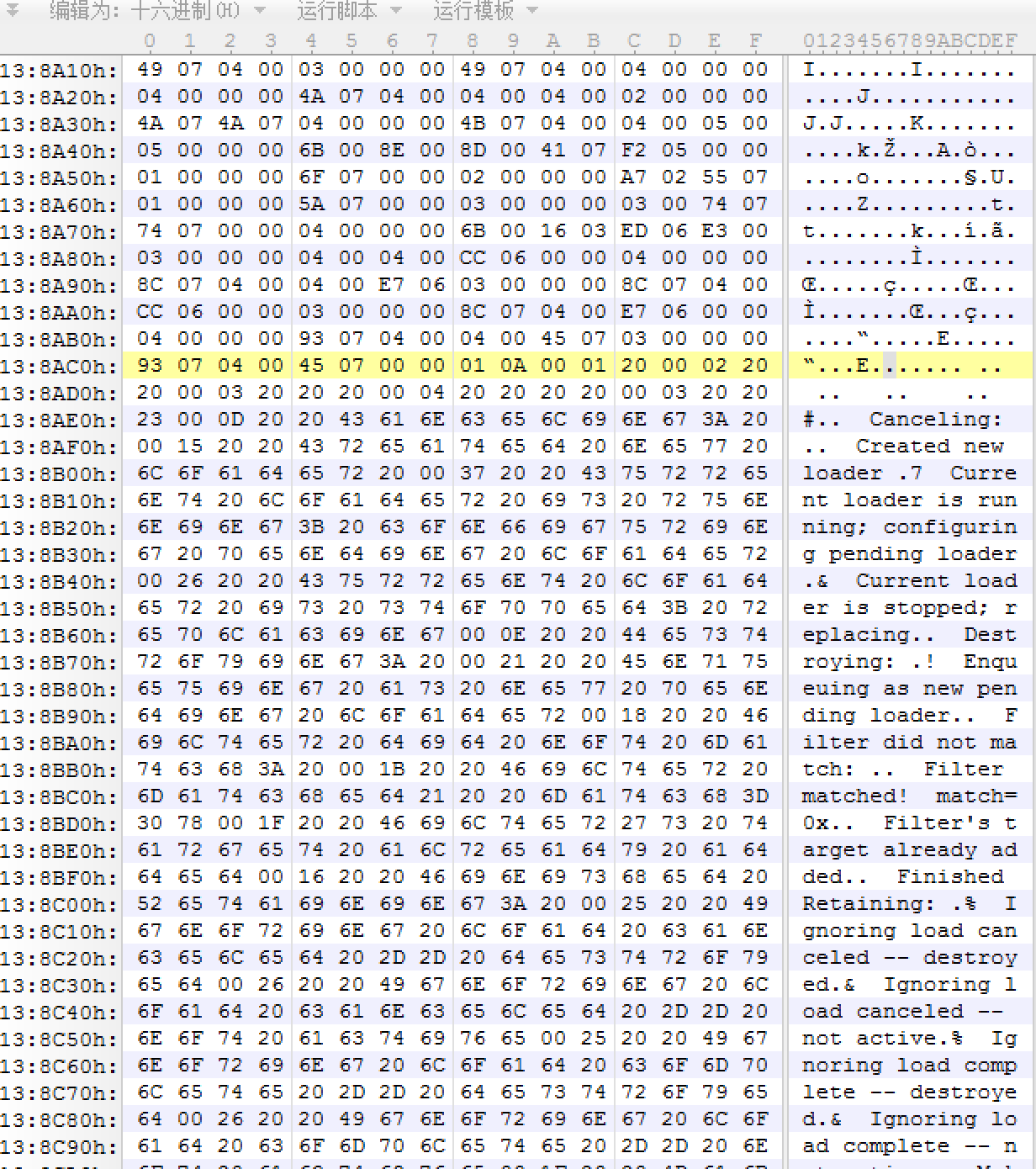
从右边可以看到,这里连续放着一堆字符串,也就表明这次操作正确了

